
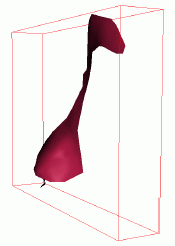
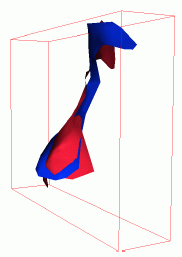
Reconstruction of the shape of a giraffe's neck and shoulder. Left: Excerpt from an image sequence. Middle: Average pose. Right: Modes of variation.
This paper addresses the problem of recovering 3D non-rigid shape models from image sequences. For example, given a video recording of a talking person, we would like to estimate a 3D model of the lips and the full face and its internal modes of variation. Many solutions that recover 3D shape from 2D image sequences have been proposed; these so-called structure-from-motion techniques usually assume that the 3D object is rigid. For example Tomasi and Kanade's factorization technique is based on a rigid shape matrix, which produces a tracking matrix of rank 3 under orthographic projection. We propose a novel technique based on a non-rigid model, where the 3D shape in each frame is a linear combination of a set of basis shapes. Under this model, the tracking matrix is of higher rank, and can be factored in a three step process to yield to pose, configuration and shape. We demonstrate this simple but effective algorithm on video sequences of people and animals. We were able to recover 3D non-rigid facial models with high accuracy.
Example
CVPR 2000 paper:
Compressed Postscript (1.5MB)
PDF (13MB)